CNCF Sandbox · Scale-to-zero for HTTP services
Automatically scale your services to zero when idle and scale up when traffic arrives.
A Kubernetes-native operator that saves cost using scale-to-zero without losing any traffic, requires no code changes, and integrates with your existing Kubernetes infrastructure.
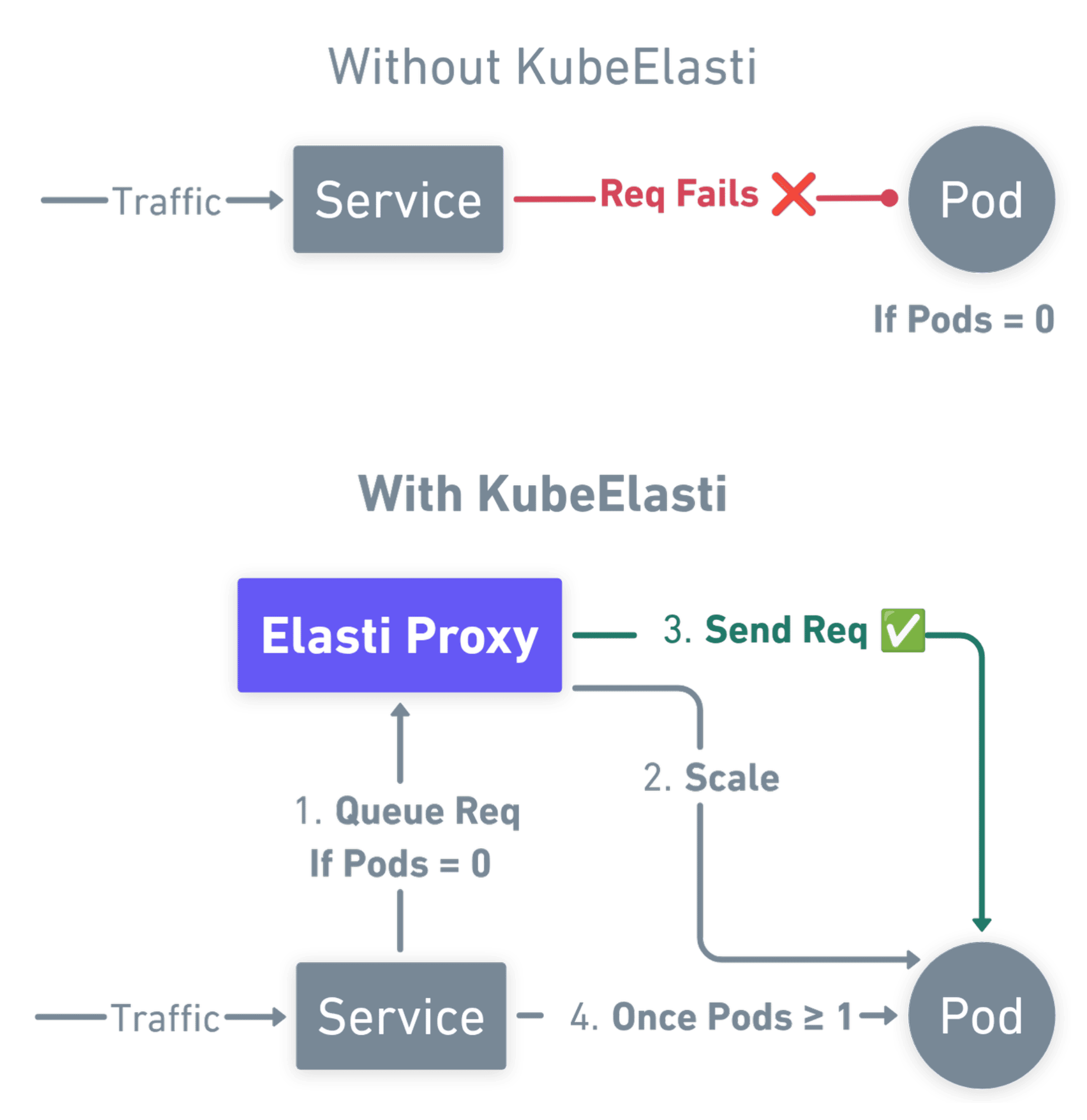
Queue-aware resolver holds HTTP requests while the first pod comes online.
Prometheus queries and thresholds decide when it is safe to scale to zero.
Works with the ingress and mesh you already run, no new programming model.
Product
Built for real clusters
Scale-to-zero without replacing your ingress, mesh, or workloads.
Save cost
Turn off pods when triggers say the workload is idle. Cooldowns and optional windows keep behaviour predictable.
Wake path that preserves requests
Proxy mode queues traffic at zero replicas, then hands off to pods in serve mode when ready.
One CRD to adopt
ElastiService references your existing Service, Deployment, StatefulSet, or Argo Rollout.
HPA and KEDA friendly
Scale from zero with KubeElasti; let HPA or KEDA own 1→N. Optional KEDA pause keeps ScaledObjects from fighting idle scale.
Observable by default
Prometheus metrics for operator and resolver; wire ServiceMonitors when you enable chart monitoring.
Probe responses at zero replicas
Answer health checks from the resolver so load balancers stay green without forcing a scale-up.
Lifecycle
From steady traffic to cold start
Four beats that match how the controller and resolver cooperate.
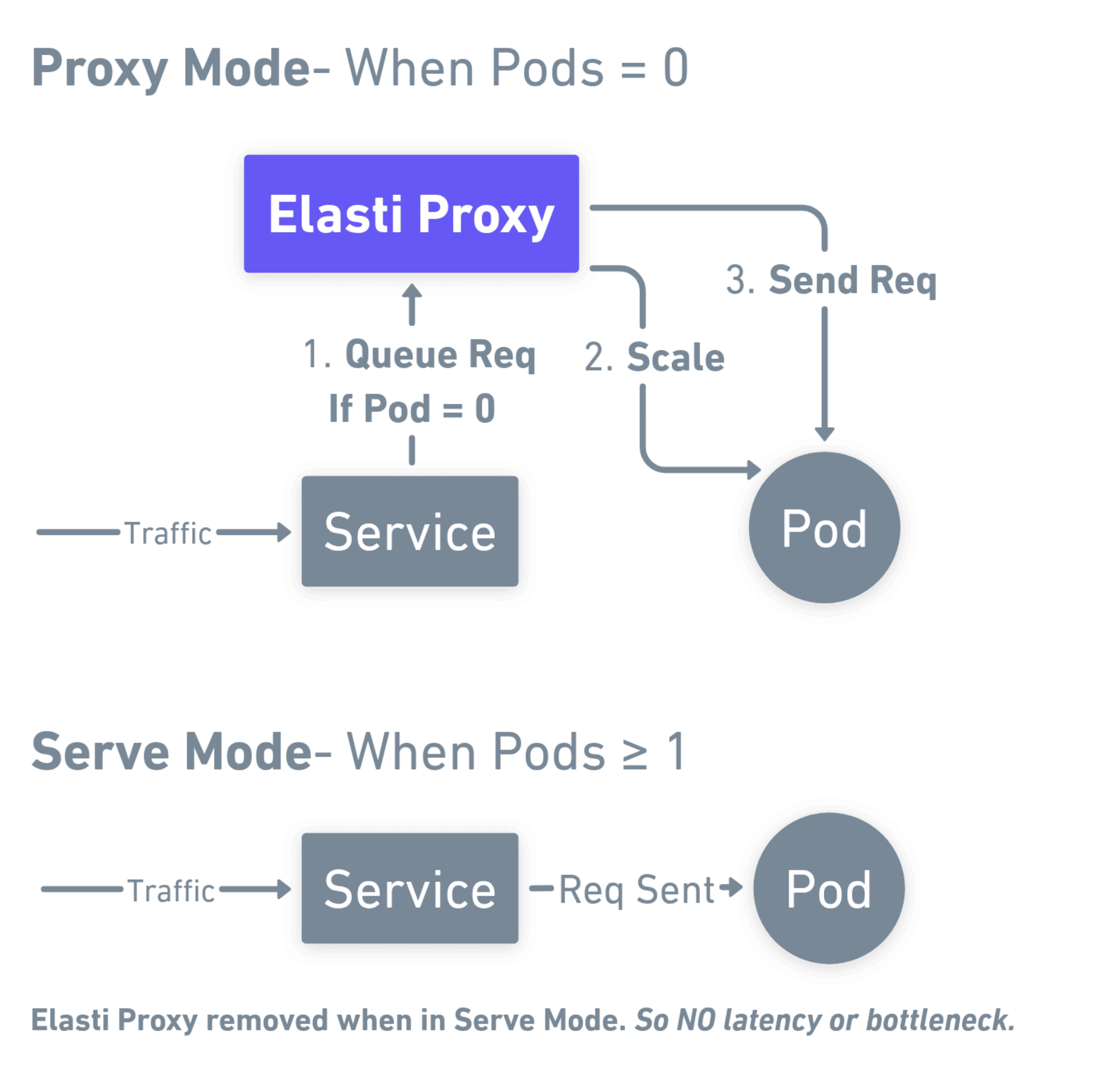
Scale down
When triggers stay under threshold, replicas go to zero and the Service shifts to proxy mode.
Queue at the edge
The resolver accepts HTTP, matches optional probe rules, and queues everything else.
Scale up
First meaningful request notifies the operator; workloads return to minTargetReplicas.
Serve mode
Endpoints point at live pods again; queued work drains and the data path stays direct.
Install
Scale-to-zero with just one file
Replace placeholders, apply, then follow the full Helm guide for production defaults.
# Create an ElastiService for the workload you want at zero when idle
# Replace placeholders, then: kubectl apply -f elasti-service.yaml
kubectl apply -f - <<EOF
apiVersion: elasti.truefoundry.com/v1alpha1
kind: ElastiService
metadata:
name: <TARGET_SERVICE>
namespace: <TARGET_SERVICE_NAMESPACE>
spec:
minTargetReplicas: 1
service: <TARGET_SERVICE_NAME>
cooldownPeriod: 5
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: <TARGET_DEPLOYMENT_NAME>
triggers:
- type: prometheus
metadata:
query: sum(rate(nginx_ingress_controller_requests[1m])) or vector(0)
serverAddress: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
threshold: "0.5"
EOF
Watch
See KubeElasti in action
Walkthrough of install, triggers, and a live scale-to-zero path.
Community
Build with us
Issues, design notes, and adopters all land in the open.
Project status
We are a Cloud Native Computing Foundation sandbox project.
KubeElasti was originally created by TrueFoundry.
KubeElasti is developed in the open with community discussions, issues, and pull requests in the project repository.